Transformer를 제대로 알고 있는가? 를 답하고 싶어 쓰기 시작한 글이다.
처음 논문 리딩을 시작할 때 Attention is All You Need 논문이 어려워 당황했던 경험을 생각하며 써본다.
대단한 숫자인 인용 수 148,074회의 "Attention is All You Need" 2017 논문을 중심으로 완전 파악해보자.
Transformer의 목적은?
논문의 Abstract.
"Transformer는 sequence transduction model의 기존 토대가 되는 recurrent(RNN)이나 convolutional neural network(CNN)를 사용하지 않는 새로운 네트워크 구조이다."
sequence transduction은 시퀀스를 input하고 시퀀스를 output한다는 것이다.
시퀀스는 순서가 있는 요소들의 집합을 생각하면 된다.
(sequence transduction model = sequence to sequence(seq2seq) model)
예를 들면 문장도 시퀀스이다. 단어들의 순서가 있으니까.
sequence transduction task의 예시로는 번역, 챗봇 등이 있다.
기존 RNN, CNN은 데이터를 순차적으로 따라가거나 지역적 패턴을 학습하는 방식인데 트랜스포머는 그럴 필요가 없음을 시사한다.
근본적인 RNN과 CNN의 단점을 없애버리는 동시에 뛰어난 성능과 가능성을 보여주었다.
Transformer 구조
트랜스포머는 encoder-decoder 구조이다.
encoder는 input sequence를 어떤 벡터로 encode하고 decoder는 이 벡터를 output sequence로 바꿔준다.
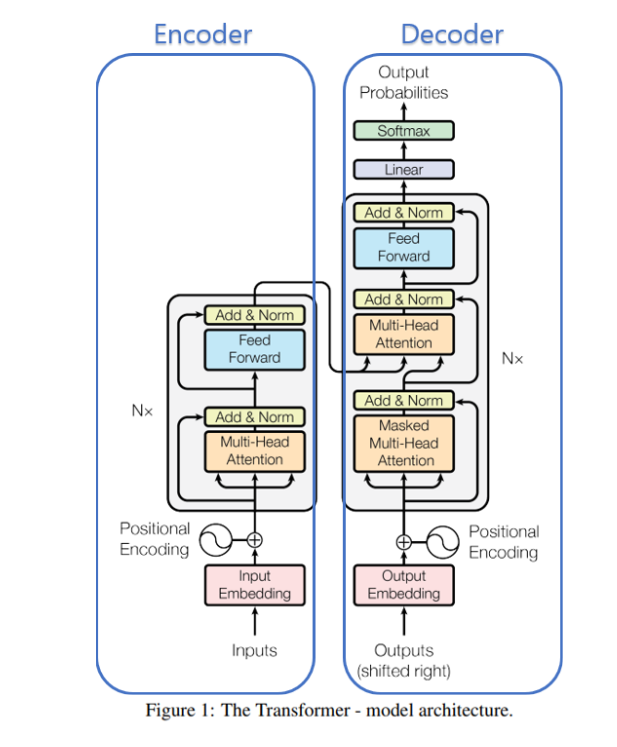

왼쪽 사진에서 input이 들어가는 왼쪽을 encoder block, ouput이 들어가는 오른쪽을 decoder block이라 하면 이 블락들은 각각 N개가 있다. (페이퍼에선 N=6)
그리고 인코더에서 나오는 정보는 다시 모든 디코더 블락에 들어가게 돼있다.
1) Token
트랜스포머로 하려는 건 입력에 시퀀스를 넣고 출력으로 시퀀스를 뽑아내는 것이다.
태스크가 영어 -> 한글 번역이라고 해보자.
input sequence는 영어 문장, output sequence는 한글 문장이 되겠다.
문장은 단어가 아닌 토큰이라는 단위로 쪼개지는데 트랜스포머에서 다루는 기본 데이터 단위이다.
아래는 토크나이저를 써서 문장들을 토큰으로 쪼갠 예시이다. 일종의 딕셔너리이다.
각각의 토큰에는 고유한 토큰 아이디가 부여된다.
이 토큰 아이디가 작을수록 더 빈번하다.
위의 예시에서도 보면 콤마와 'a'는 11, 261인 반면 제일 마지막 단어인 eternity는 109965이다.
같은 단어라도 대문자가 들어가는지, 문장에서의 위치에 따라 토큰 아이디가 달라질 수 있다.
한글의 경우 대체로 더 음절별로 토큰이 생성되는 경향이 있다.


토큰은 대부분 단어와 일치하지만 단어보다 적은 길이를 갖기도 한다.
또 기호, 이모지(의 각 바이트) 등도 토큰이 된다.
그래서 토큰의 수는 단어의 수보다 많다. 100 tokens $\simeq$ 75 words.