Abstract
오리지널 SAM보다 MobileSAM, EfficientSAM 보다 나은 EdgeSAM 제시
key idea 1)
- 새로운 knowledge distill 기법(prompts in the loop)을 적용해 ViT-based SAM image encoder를 CNN-based 구조로 distill.
- distill 과정에 prompt encoder와 mask decoder 포함.
- prompts in the loop - input에 따른 mask 생성을 더 잘 제공.
key idea 2)
- encoder에 탈부착 가능한 lightweight module 제공
- point prompt distill의 dataset bias 문제를 완화하기 위함.
Result
- 오리지널 SAM보다 37배 더 빠르다.
- edge device에서 더 높은 mIoU로 7배 빠르다.
- first variant to run 30 FPS on iPhone 14.
1. Introduction
- edge device에 직접적으로 deploy 하는 가능성을 탐구.
- 어려운 이유 1) SAM은 on-device deployment를 염두에 두고 디자인되지 않았음. (641M paramter, 2735 GFOPs under 1024x1024)
- SAM은 iphone 14에서 많은 연산과 메모리 초과로 실행 불가
- 2080 Ti에서도 throughput is 4 images/s
- 어려운 이유 1) SAM은 on-device deployment를 염두에 두고 디자인되지 않았음. (641M paramter, 2735 GFOPs under 1024x1024)
- 그렇게 하기 위해선 직관적인 솔루션은 SAM의 큰 ViT based image encoder를 더 컴팩트한 버전으로 바꾸는 것.
- MobileSAM도 그러한 접근인데 23배나 빨라지는 대신 퍼포먼스가 떨어진다.
- mask mIoU on COCO drops from 77.3 to 74.4 (ground-truth box는 box prompt)
- 또한 실질적인 deploy에서 real-time과 거리가 멀다.
- iphone 14에서 5 images/s
- EfficientSAM도 MobileSAM의 아키텍처를 따라가지만 masked image pre-training을 적용한다.
- 그래도 MobileSAM와 여전히 스피드가 비슷하고 training 시 많은 비용을 잡아먹는다.
- MobileSAM도 그러한 접근인데 23배나 빨라지는 대신 퍼포먼스가 떨어진다.
- 연구진들의 방대한 경험적 연구에 따르면 knowledge distillation (이하 KD)의 중요한 포인트는 incorporation of losses specifically tailored for dense tasks나 query-based detectors가 아니라는 것이다. 오히려 제일 중요한 건 distill 과정에서의 전략적 prompt 선택이다.
- 그러기 위한 prompt-in-the-loop 제시함으로써 SAM에 담긴 정교한 knowledge를 student model에 효과적으로 distill 한다. 어떻게 하냐면...
- student model을 multi-grained output masks of SAM과 align
- student 모델이 정확도가 떨어지는 구역에 iteratively 새로운 프롬프트를 제시.
- 이렇게 다듬어진 프롬프트들은 mask decoder를 잘 안내하며, 정확하지 않은 segmentation을 짚어낼 수 있어 학습을 향상한다.
- 또한 연구진들은 다양한 training configuration, 여러 종류의 프롬프트, encoder나 decoder를 freeze 했을 때의 효과, distillation target 선택 방법 등을 면밀히 검토했다. (더 자세한 내용은 experiment에)
- 추가적으로 ablation study을 진행함. backbone architecure 선정과 on device deployment에 중요한 throughput 성능 관점에서.
- purely CNN-based architecture들이 ViT-based 보다 optimal trade-off가 낫다.
- 왜냐하면 현재 on-device AI accelerator (예를 들어 ANE)는 대체로 CNN에 최적화되어 있기 때문이다.
- 이 발견은 연구진들의 이 prompt-aware 한 KD 접근법의 범용성을 뽑아낸다. 여러 다양한 아키텍처에 적용될 수 있음.
- purely CNN-based architecture들이 ViT-based 보다 optimal trade-off가 낫다.
- 마지막으로 탈부착 가능한 lightweight module 제안함.
- 왜냐하면 SAM은 multi-grained annotation dataset에서 훈련되었기 때문에 문제가 생김.
- 애매한(ambiguous) 프롬프트 예를 들면 single point 같은 프롬프트를 마주하면 ouput의 granularity를 판단할 때 문제다.
- COCO dataset에 중앙 포인트들이 찍힌 프롬프트를 제공받으면 instance-level 이 아니라 part-level mask 제공. 이 문제는 SAM이 teacher model 일 때 더 뚜렷해진다.
- 애매한(ambiguous) 프롬프트 예를 들면 single point 같은 프롬프트를 마주하면 ouput의 granularity를 판단할 때 문제다.
- 제안한 모듈은 주어진 테스트 세트나 application 시나리오에 따른 granularity priors(기준)에 따라 명확하게 타깃을 구분하고 적응하도록 한다.
- 이 모듈은 다양한 레벨의 prompt 애매함(ambiguity)에도 정확히 해석하고 반응하는 SAM의 성능을 향상한다.
- 왜냐하면 SAM은 multi-grained annotation dataset에서 훈련되었기 때문에 문제가 생김.
마지막으로 EdgeSAM은 매우 뛰어난 성능 향상을 보였다. (이하 생략)
2. Related Work
Efficient Model Design - efficient CNNS, transformers..
- 이 연구는 다양한 efficient backbone 들에 적용될 수 있기 때문에 orthogonal 하다~
Knowledge Distillation in Detection and Segmentation
- 흔한 접근은 teacher와 student model의 dense feature들 사이의 pixel-wise 나 channel-wise 한 작용을 레버리지 하는 것.
- 최근에는 query-based detectors를 위해 특화된 KD loss를 디벨롭하는 것이 이슈다. (DETR)
- MobileSAM → SAM 인코더와 컴팩트한 backbone사이의 pixel-wise feature distillation 실시.
- prompt encoder와 mask decoder를 제대로 address 하지 않음.
- 따라서 오리지널 SAM에 비해 심각한 performance 하락을 초래함.
- prompt encoder와 mask decoder를 제대로 address 하지 않음.
- FastSAM은 SA-1B dataset을 사용하는 YOLACT-based 모델.
- post-process object selection을 위해 휴리스틱한 규칙들을 세움.
- SAM의 원칙과 부분적으로 부합.
- post-process object selection을 위해 휴리스틱한 규칙들을 세움.
- Efficient SAM은 선행되는 연구로 masked image pre-training 한 좋은 trade-off이지만 큰 연산 비용이 들고 image encoder는 MobileSAM과 다를 바가 없어서 실행에도 더 빨라지지 않는다.
- 이 연구는 training과 inference 예산을 더 제한해 탐구한다.
Efficient Segmentation Models.
- 선행 연구들은 대체로 특정한 도메인 내의 closest segmentation에 집중한다. (그중에서도 특히 운전하는 상황)
- 최근에는 몇 연구는 on-device implementation에 적합한 segmentation model을 디자인하는 것을 탐구. mobile platform 같은.
- 그렇지만 on-device segmentation은 아직 많이 탐험되지 않았음.
- MobileSAM이 그 시도 중 하나지만 연산, 퍼포먼스 한계가 있으므로 더 많은 연구가 진전되어야 함.
3. Methods
- encoder distillation
- prompt in the loop distillation
- lightweight module for granularity preferences (탈부착)
3.1 SAM
- SAM 구조와 흐름 설명… (생략).
- SAM은 ViTDet의 backbone design을 따른다.
- SA-1B에 대해서 유념할 특성들.
- mask annotation들은 ambiguity-aware 한 모델을 프롬프트함.
- masks는 class-agnostic 하다. (클래스를 모르는)
- annotation들은 multigrained 하다 - instance level & part level에서.
- 그래서 다른 segmentation 모델들과 다르게 이 데이터셋으로 distillation 하는 게 어렵다.
3.2 EdgeSAM
목표는 SAM의 능력을 transfer 해서 더 컴팩트한 모델을 만드는 것. 최대한 edge device에 deploy 할 수 있도록.
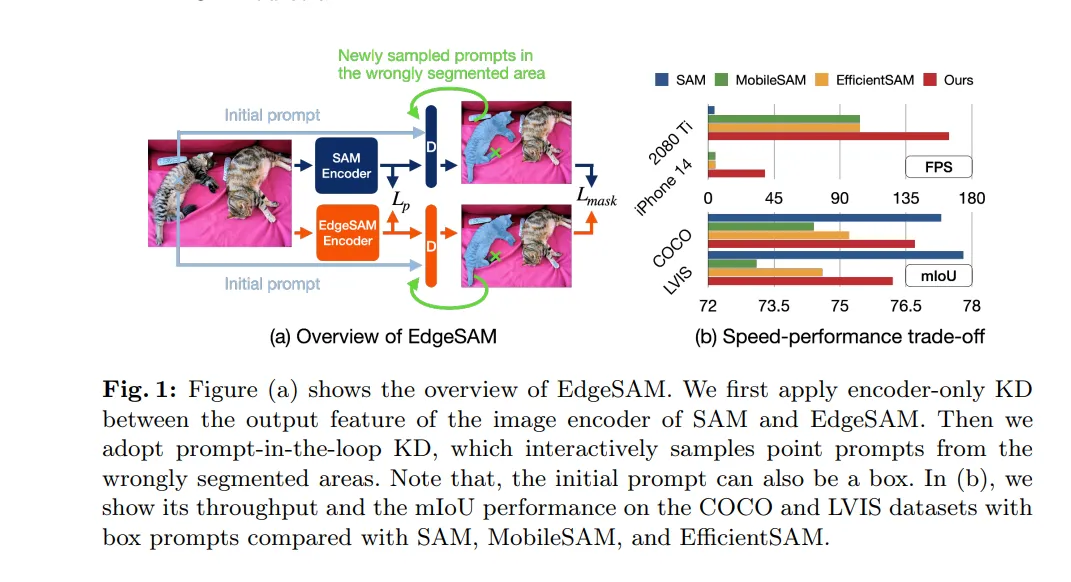
EdgeSAM은 SA-1B dataset의 1%만 사용해 훈련하고 그 zero-shot transferability를 COCO dataset과 LVIS dataset으로 evaluate.
Encoder-Only Knowledge Distillation
- MobileSAM과 마찬가지로 앞서 말한 pixel-wise feature distillation loss를 계산. $L_p$ 는 loss, T는 teacher(SAM image encoder)와 S는 student. $I$는 input image
- $$L_p =MSE(T_{enc}(I), S_{enc}{I})$$
- student 모델의 downsampling stride와 feature channel이 teacher와 align 하지 않음.
- MobileSAM은 그래서 downsampling 연산 두 단계를 제거하는 대신에 projection layer로 channel 차원을 align 해줌.
- 우리는 downsampling layer도 유지하고 projection layer도 사용함.
- 대신 작은 FPN을 만들어서 feature를 필요한 resolution으로 upsample 한다. 그리고 element-wise addition으로 이전 단계의 feature와 더한다.
- 다양한 efficient backbone들을 살펴보았지만 항상 심각한 performance 갭이 있음.
- 더 긴 기간?(schedule) 동안 학습하거나 dense prediction tasks를 위해 디자인된 distillation loss를 계산하는 건 무의미함.
- 따라서 prompts-in-the loop을 제안해 task-specific 한 가이드를 주고자 함.
Prompt-In-the-Loop Knowledge Distillation
mask decoder는 충분히 lightweight하니 구조는 내버려두지만 그 안을 재조명하자.
- mask decoder는 two-stream 양방향 transformer다.
- 한 stream으로는 image encoder에서 나온 output feature map $f$ 가 들어가고 다른 stream에는 sparse prompt embeddings $p$가 네 개의 mask token 들 $m$ 과 iou token $c$ 와 concatenate 돼서 들어간다. sparse prompt은 points과 box의 무수한 조합 중 하나다.
이런 input을 가지고 teacher와 student 모델 사이에서 distill 하는 target이 될 수 있는 것들을 여러 개가 있다. refined feature map, mask/IoU tokens, cross attention between two streams of the inputs, 그리고 output mask logits.
실험을 통해 teacher mask output을 ground truth로 사용해서 student를 supervise 하는 것이 제일 효과적임을 밝힌다. (더 많은 디테일은 appendix)
여기서 $\phi$는 binary thresholding, $f_t, f_s$는 teacher와 student의 feature를 말한다. $L_{mask}$에는 Dice loss와 BCE loss. jointly learn 하기 위해서 image encoder로의 gradient 역전파 허용.
$$L_d = L_{mask}(\phi((T_{dec}(f_t, p, m, c), S_{dec}(f_t, p, m, c))$$
teacher와 student는 같은 p, m, c를 공유하며 train 시에는 frozen 되어 있다.
distillation loss는 매우 심플하지만 각 training iteration마다의 prompt selection은 면밀히 디자인되어야 한다.
- mask decoder를 fine tuning 하는 것은 zero-shot 생성 능력을 해칠 수 있다는 것을 발견했다. 특정한 조합의 프롬프트로 training 하는 것은 training 때 사용되지 않는 프롬프트 조합으로 inference했을 때의 성능을 악화시킬 수 있다는 뜻이다. 예를 들면 point들로만 training하는 것은 box prompts로 테스트했을 때 현저한 성능 드랍을 가져온다.
- mask decoder를 freeze 하는 것이나 LoRA를 decoder에 사용해 규제(regulation) 하는 것이 문제를 완화하긴 하지만 performance upper-bound를 제한한다.
- 또한 오리지널 SAM도 single point같이 애매한 prompt가 제공되었을 때 그닥인 mask prediction을 보인다.
- COCO center point일 때 mask mIoU only 53.6
- 따라서 이런 경우에 student output을 align 하는 것은 최적의 방법이 아닐 수 있다.
distill을 더 잘하기 위해서 dynamic prompt sampling 전략을 소개한다.
- 동적으로 다양한 세트의의 prompt 조합을 생성한다. (box or point)
- student model이 틀리는 masks 정확하게 짚어내게 한다(identify).
- teacher model이 정확한 가이드를 줄 수 있도록 더 질 높은 mask를 생성하게 한다.
최근 연구에서 영감을 얻어서 이 전략은 distill 과정에서 새로운 prompt를 매 횟수마다 샘플링한다.
시작은 초기 prompt로 시작한다. 그리고 동일한 확률 아래 (SA-1B에서 주어진 박스든 포인트든) teacher와 student 모델의 decoder에 들어간다. 그리고 teacher와 student의 mask prediction이 달라지는 구역을 관찰한다. Fig.2에 나와있는 것처럼 teacher의 output을 레퍼런스 삼아 새로운 prompt를 sample 한다. (false negative로 표시된 positive point나 그 반대.)
이런 새롭게 샘플링된 포인트는 그다음 decoding iteration에 들어갈 프롬프트들과 같이 들어가게 된다. (알고리즘 수도코드는 Appendix D에서)
- 각각의 프롬프트는 다양한 레벨의 granularity를 커버하는 네 개의 mask prediction에 도달할 수 있어야 한다.
- 연구 analysis 결과 제일 높은 IoU score를 가진 teacher mask와 해당하는 student mask 사이의 disagreement(불일치?)를 계산한다.
요약하면 이 발견은 dense prediction이나 query-based distillation 접근에 의존하기보다 동적으로 적절한 prompt 조합을 mask decoder에 feeding 함으로써 더 효과적으로 distill 함을 보여준다. prompt-in-the-loop distillation 전략은 프롬프트의 전략적 사용을 우선시한다. Experiment ablation study에 더 자세한 내용.
- Granularity Priors
- 심플하고 효율적인 모듈을 제공한다. (탈부착)
- 제공 이유:
- SA-1B는 class-agnostic, multi-grained에다가 자동으로 라벨 된 데이터셋이다. 그래서 annotation 분포가 사람 손으로 일일이 만든 dataset(COCO)과 매우 다를 수 있다. 그래서 single point와 같은 모호한 프롬프트는 필요한 output granularity에 못 미칠 수 있다. (box 프롬프트는 SAM이 잘 추출함.) 또한 box에 여러 번 클릭하고 반응하는 것과 달리 스마트폰에서는 단일 클릭, click-and-drag이 선호된다.
- 오리지널 SAM처럼 사용하길 원하면 끄면 됨.
- lightweight 한 region proposal network(RPN)을 만든다. (image encoder frozen 된 그 위에)
- 이건 feature pyramid network (FPN)과 shared detection head로 구성되어 있으며 COCO라는 특정한 dataset에 train 되었다. (granularity prior를 더 잘 캡처하기 위함)
- inference 될 때, proposal box들을 병합하는데 그 box들의 중심점들은 point prompts들의 k nearest neighbors들이다. 박스들이 병합될 때는 그들의 confidence score에 따라 가중된다.
- 그리고 병합된 박스는 point input과 합쳐져 mask decoder에 들어가는 prompt가 된다.
3.3 Training and Application
- Training Pipeline (세 단계)
- encoder-only KD를 1%의 SA-1B에 실시. (MobileSAM과 마찬가지)
- prompt-in-the-loop distillation. 같은 데이터셋을 사용하는데 point와 box prompt도 함께.
- (선택적) lightweigt RPN을 제외한 module들을 얼리고 class-agnostic 한 ground-truth boxes들로 train 한다. (focal loss와 Hubal loss 사용)
- Inference and On-Device Demo
- EdgeSAM은 point나 box prompt를 사용해 inference 할 수 있으며 SAM과 마찬가지로 점진적으로 포인트들을 추가할 수 있다.
- on-device demo 제공. 꼭 해보길 권함.
4 Experiments

(생략)
5. Conclusion and Discussion
이 페이퍼에서는 EdgeSAM을 제안한다. edge device에서 real-time으로 실행될 수 있는 첫 SAM으로 의의가 있다.
- distill SAM into a lightweight CNN-based architecture
- prompt-in-the-loop KD 제안.
- 기존 distill 방법들은 image encoder만 포함시키는데 그러면 task-agnostic 하다. student model에 distill이 잘 이루어질 수 없다.
- 따라서 SAM의 encoder와 decoder를 모두 고려하고 task에 기여할 수 있는 정보를 제공한다.
- 다양한 실험으로 증명
EdgeSAM이 edge device들에서 뛰어난 스피드를 보이지만 연구할 영역은 남아있다.
- quantization, model pruning, on-device optimization, mixed-precision inference, etc
- 또한 training 때 augmentation은 실시하지 않았다.